
Comprender los grandes datos

El término Big Data apareció por primera vez en 2000 por un analista de la industria de Occidente llamado Doug Laney. A nivel mundial, Big data son datos sobre muchas cosas que se recopilan en volúmenes muy grandes a gran velocidad. Los grandes datos se pueden analizar y procesar con fines de toma de decisiones (toma de decisiones), estrategia empresarial y predicción empresarial.
En la terminología clásica de gestión de datos, debido a su creciente volumen, Big data puede considerarse como datos que no pueden ser resueltos por base de datos (base de datos), así como las aplicaciones tradicionales de procesamiento de datos. ¿Por qué somos tan ofensivos? base de datos? Porque en su implementación, el concepto de Big Data se puede denominar como base de datos de tamaño muy grande, Base de datos muy grande (VLDB) cuya configuración utiliza Sistema de administración de base de datos (SGBD).
En un big data, datos mixtos entre datos estructurados y datos no estructurados. Si cree que NoSQL es lo suficientemente complicado, Big Data es decenas de veces más complicado que eso. Incluso si hay un programa o una aplicación diseñada específicamente para administrarla, la aplicación requiere un diseño de algoritmo y consulta que no es común.
Marco de referencia y las aplicaciones utilizadas para gestionar el big data no están directamente vinculadas a todos los datos, sino que utilizan métodos analíticos. Marco de referencia o aplicaciones para administrar grandes datos se conoce comúnmente como ‘marco de análisis de aplicaciones de big data‘ pero también hay quien lo llama ‘grandes herramientas de datos‘ sólo.
Beneficios de los grandes datos
Los grandes datos solo pueden ser útiles después del análisis. Podemos hacer una analogía del análisis aquí en marco de referencia que es mucho más pequeño, como cuando hacemos consulta contra la base de datos en el servidor SQL. Sin embargo, en una escala de datos muy grande y masiva, los tipos de datos serán más variados, el volumen de datos será mayor y la estructura será más compleja. Desde que se inició, implementó y desarrolló el concepto de esta tecnología marco de referenciaSegún él, Big data ha sido capaz de proporcionar beneficios para la vida humana.
Citando información de techinasia.com, aquí hay un breve resumen de ejemplos del uso de Big Data en Indonesia que se presentó en la conferencia ‘Big Data Week Indonesia’ en 2015 (hace 4 años).
1. Sistema de información agrícola
Regi Wahyu, director general de Mediatrac, una gran empresa de análisis de datos, reclutó a varios estudiantes talentosos de la Universidad de Padjadjaran para realizar una investigación en un área de campo de arroz en Java Occidental.
La información obtenida de los resultados de estas investigaciones se recopila en Big Data que los agricultores pueden utilizar para aumentar la producción de cultivos, predecir el momento adecuado para plantar cultivos y otros.
2. Sistema de información tributaria
El análisis de big data en la Dirección General de Impuestos (Dirección General de Impuestos) aún se encuentra en etapa de desarrollo. Se espera que el análisis de big data resuelva los problemas relacionados con la baja conciencia del público en el pago de impuestos.
El jefe del Director General de Impuestos en ese momento, Iwan Djuniardi, en su presentación de demostración mostró visualizaciones detalladas como el análisis del árbol genealógico, los tipos y activos de la riqueza, así como los tipos de impuestos y el estado del pago de impuestos.
3. Sistema de información de desastres
Quick Disaster es una aplicación para Google Glass que ayudará a los usuarios durante y después de que ocurra un desastre. Por ejemplo, cuando ocurre un terremoto, Google Glass proporcionará información sobre lo que los usuarios deben hacer y luego brindará recomendaciones para las rutas de evacuación después de que ocurra un desastre. La aplicación Quick Disaster fue desarrollada por un investigador de la Universidad Gajah Mada (UGM) llamado Daniel Oscar Baskoro.
4. Sistema de información de salud
Aún desde la UGM, una investigadora del sector salud llamada Anis Fuad, explicó que las clínicas y hospitales en Indonesia todavía usan sus propias aplicaciones para registrar los datos de los pacientes. Los datos enviados a la Secretaría de Salud aún son mínimos e incompletos.
Al utilizar el análisis de Big Data para el sector de la salud, mejorará la precisión de la predicción de enfermedades y el nivel de salud de la población en todo el país de manera centralizada. Actualmente, el problema se está siguiendo lentamente con el inicio de la construcción. base de datos en el sistema BPJS en línea.
5. Sistema de información lingüística
Ruli Manurung de la Universidad de Indonesia (UI) dijo que podemos clasificar y agrupar millones de palabras en indonesio utilizando Big Data. Además, también se puede usar para mapear oraciones para admitir aplicaciones de traducción de idiomas extranjeros al indonesio o viceversa.
Características del Big Data (5V)
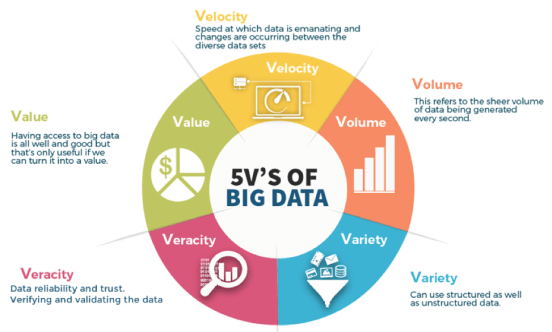
Big data tiene un carácter básico de 3V, a saber Volumen, Velocidad, y Variedad. Sin embargo, en su desarrollo se agregó nuevamente Valor y Veracidad, por lo que se sabe que la corriente tiene un carácter básico de 5V. A continuación se describen las cinco características.
1. Volumen
Esto significa que un conjunto de datos en la cantidad y volumen muy grande ya veces desestructurado. Por ejemplo, feeds de Twitter, feeds de Instagram, datos de texto de chat y estados de Whatsapp, flujo de clics usuario De la página web. El flujo de estos datos puede ser de hasta miles de Terrabytes (TB) por segundo.
2. Velocidad
Se puede acceder a los datos a una velocidad muy rápida para que se puedan usar de inmediato. Desde la era almacenamiento en la nube y computación en la nube En los últimos años, los usuarios de Internet han experimentado esta facilidad de velocidad de acceso a datos.
Una de las pruebas, entre otras, es la existencia de un sistema operativo en línea basado en Microsoft Silverlight, aplicaciones de oficina (oficina) establecido web como Office365, almacenamiento en la nube como Dropbox y GDrive, velocidad de acceso a la página web Basado en Javascript, basado en aplicación de dibujo de diseño web como Pixlr, aplicaciones desarrollador Aplicaciones Android basadas web como Kodular y MIT App Inventor, aplicaciones de diseño diagrama de flujo como Draw.io, y muchos más.
3. Variedad
Esto significa que contiene varios tipos archivos, tanto estructurados como no estructurados. El análisis de datos no estructurados requerirá algoritmos ligeramente diferentes, como datos de texto, imagen, sonido y video.
Para tales datos, llevará más tiempo procesarlos, porque podría ser que en los datos no estructurados todavía haya otros datos o nuevos datos que se puedan extraer. Por ejemplo, en los datos MP3 hay IDv1 y Etiquetas IDv2, en los datos JPEG hay datos sobre el tipo de cámara utilizada, en los datos PDF está el nombre de la aplicación que lo hizo, y mucho más.
4. Valor (Marcos)
Intento de valor es cuán valiosos o significativos son los datos. Por ejemplo, los datos biográficos de los empleados de una empresa de impresión no tendrán valor a efectos del análisis predictivo de la aceptación de los empleados en las empresas farmacéuticas.
Los datos pueden ser poco importantes y sin valor en un caso, pero pueden ser muy importantes y muy valiosos en otro. Los datos que no tengan ningún valor en ningún caso serán filtrados en los sistemas de aplicación de análisis de Big data.
5. Veracidad (Honestidad)
Personaje veracidad se refiere a cuán precisos y confiables son los datos. Continuando con un ejemplo en el punto valor arriba, podría estar en el archivo MP3 Etiquetas IDv1se ha modificado para que se cuestione la autenticidad del archivo MP3, cambios Etiquetas IDv1 puede ser por los resultados producción aplicación de procesamiento de sonido o convertidor de archivos MP3. Los datos que no tengan el carácter de honestidad o autenticidad no serán filtrados al sistema de análisis.
Ejemplo de aplicación Marco de referencia Análisis de grandes datos

Apache Hadoop es una colección de aplicaciones fuente abierta que se utiliza para recopilar y analizar datos de servicio en línea. Muchos lo llaman solo Hadoop. Hadoop comenzó a fabricarse alrededor de 2005, lanzado oficialmente en 2006 con el nombre oficial Apache Hadoop.
Hadoop está diseñado utilizando el lenguaje de programación Java, por lo que puede ejecutarse en varias plataformas/sistemas operativos. Hadoop es una colección de aplicaciones que pueden actuar como módulo básico, submódulo, ecosistema o colección de un paquete de software adicional (adicional) que se puede instalar encima o junto al propio sistema Hadoop principal. La colección de aplicaciones de Hadoop incluye: Apache Pig, Apache Hive, Apache HBase, Apache Phoenix, Apache Spark, Apache ZooKeeper, Cloudera Impala, Apache Flume, Apache Sqoop, Apache Oozie y Apache Storm.
La historia y el concepto de Big Data comenzó en la década de 1970, ese fue el momento en que las personas de tecnología de la información comenzaron a abrir sus horizontes al análisis de datos y su relación con la ciencia estadística. Continuó hasta el año 2000, cuando las redes sociales comenzaron a crecer rápidamente, haciendo que las personas fueran más conscientes de la importancia del análisis de datos en estas plataformas de redes sociales.
Los datos ingresados en las redes sociales son demasiado grandes para ser almacenados y procesados en un medio de almacenamiento centralizado. Luego, lentamente surgieron nuevas tecnologías para resolver este problema, nació el concepto de NoSQL que se desarrolló en Apache Cassandra y marco de referencia Análisis de big data en Apache Hadoop.
Esa es una explicación del significado de big data junto con los beneficios y ejemplos de aplicaciones que se pueden usar para analizar big data. ¡Ojalá sea útil y fácil de entender!

